Duplicate orders are one of the quietest ways an algo account bleeds. The strategy looks fine on paper, the backtest is clean, but the live P&L shows two entries when there should be one — sometimes three. By the time you spot it, you are either over-leveraged or staring at a margin call.
This post explains why duplicates happen in webhook and broker-API workflows, and what to put in place so they stop happening.
Why duplicate orders show up in live trading
Most retail algo setups look the same: a signal source (TradingView, scanner, custom script) fires an alert, that alert hits a webhook, the webhook talks to a broker API, and the broker places the order. Every hop in that chain can produce a duplicate.
The common causes:
- Signal source fires twice. TradingView alerts can re-fire on bar close vs intra-bar, or if you have the same alert configured on two timeframes. Pine
strategy.entrycalls can also re-trigger ifpyramidingis non-zero. - Webhook retries. If your webhook receiver doesn't respond with HTTP 200 fast enough, the sender retries. The original request may have succeeded — you just didn't acknowledge in time.
- Network timeouts to the broker. Your code sends the order, the request times out, you assume failure and resend. The broker actually received both.
- Process restarts. A crash-restart loop replays the last in-flight signal. Without persistent state, your code has no memory of what was already sent.
- Multiple instances running. You forgot to kill the old script on the VPS, or staging and prod are both subscribed to the same signal channel.
- Manual + algo overlap. You place a hedge manually, the algo also tries to hedge based on its rules. Not a bug, but the effect on margin is identical.
The pattern across all of these: the system has no reliable way to answer the question "have I already acted on this signal?"
Idempotency: the one idea that fixes most of this
Idempotency means an operation produces the same result whether you run it once or ten times. For order placement, that translates to: every order request carries a unique ID, and the broker (or your middleware) refuses to place a second order with the same ID.
In practice:
- When a signal arrives, generate a deterministic
client_order_id— something likeNIFTY_25MAY26_22500CE_BUY_1430(instrument + expiry + strike + side + signal timestamp rounded to the bar). - Send that ID with every order request to the broker API.
- If the broker supports
client_order_iddeduplication (Zerodha'stag, Dhan'scorrelation_id, etc.), the second request fails cleanly instead of placing a second order. - If the broker does not enforce dedup, your middleware must. Maintain a local set of seen IDs in Redis, SQLite, or even a flat file with file locks.
The key word is deterministic. If the ID is uuid4(), retries get new IDs and the dedup is useless. The ID must be a function of the signal, not the request.
Order state tracking: the second half of the fix
Idempotency stops duplicate sends. State tracking stops duplicate decisions.
Before your algo decides to enter, it should check its own ledger:
- Is there already a pending order for this instrument and side?
- Is there an open position that this signal would add to (when it shouldn't)?
- Was this exact signal acted on within the last N seconds?
A minimal state table per strategy needs: signal ID, instrument, side, quantity, order ID returned by broker, status (pending, filled, rejected, cancelled), and timestamps. Update it on every broker callback or every poll cycle. Don't trust in-memory dictionaries alone — persist to disk so a restart can rehydrate.
This is also what makes a live monitoring layer actually useful. A monitor that only watches P&L is blind to the case where two orders fired but only one shows in the UI you're looking at.
Webhook-specific traps
If your signals come through TradingView webhooks, a few things to harden:
- Ack fast, process async. Return 200 immediately, then process the payload in a background worker. Slow handlers cause the sender to retry.
- Rate limit at the receiver. If the same payload arrives twice within, say, 2 seconds, drop the second. Most retail signal sources will not legitimately fire the same alert that fast.
- Sign your payloads. A shared secret in the alert body, validated server-side, stops a stray webhook URL from being abused — and avoids the "why did my algo trade at 3am" puzzle.
- Log every received payload before any logic runs. When something goes wrong, you need the raw input, not just the parsed version.
Broker API-specific traps
Working directly with a broker API brings its own failure modes:
- Timeouts are not failures. Treat HTTP 5xx and connection timeouts as unknown state, not as failed. The right next step is to query the orderbook for your
client_order_id, not to resend. - Token expiry mid-day. Some broker tokens expire daily; some refresh silently; some don't. A re-auth in the middle of a retry loop can replay the original request. Wrap auth refresh in its own state machine.
- Order-update streams can drop. If you rely only on WebSocket order updates, a dropped connection means you miss a fill confirmation and may treat the order as still pending. Poll the orderbook as a fallback every few seconds.
A practical checklist
Before you let any strategy go live, walk through this:
- Every order request carries a deterministic
client_order_idderived from the signal. - The middleware refuses to send a second order with the same ID within the same session.
- Order state is persisted to disk, not just held in memory.
- Webhook handler responds 200 in under 1 second; heavy work runs async.
- Only one instance of the strategy can run at a time (lock file, systemd, or container-level).
- Network timeouts trigger an orderbook lookup, never an automatic resend.
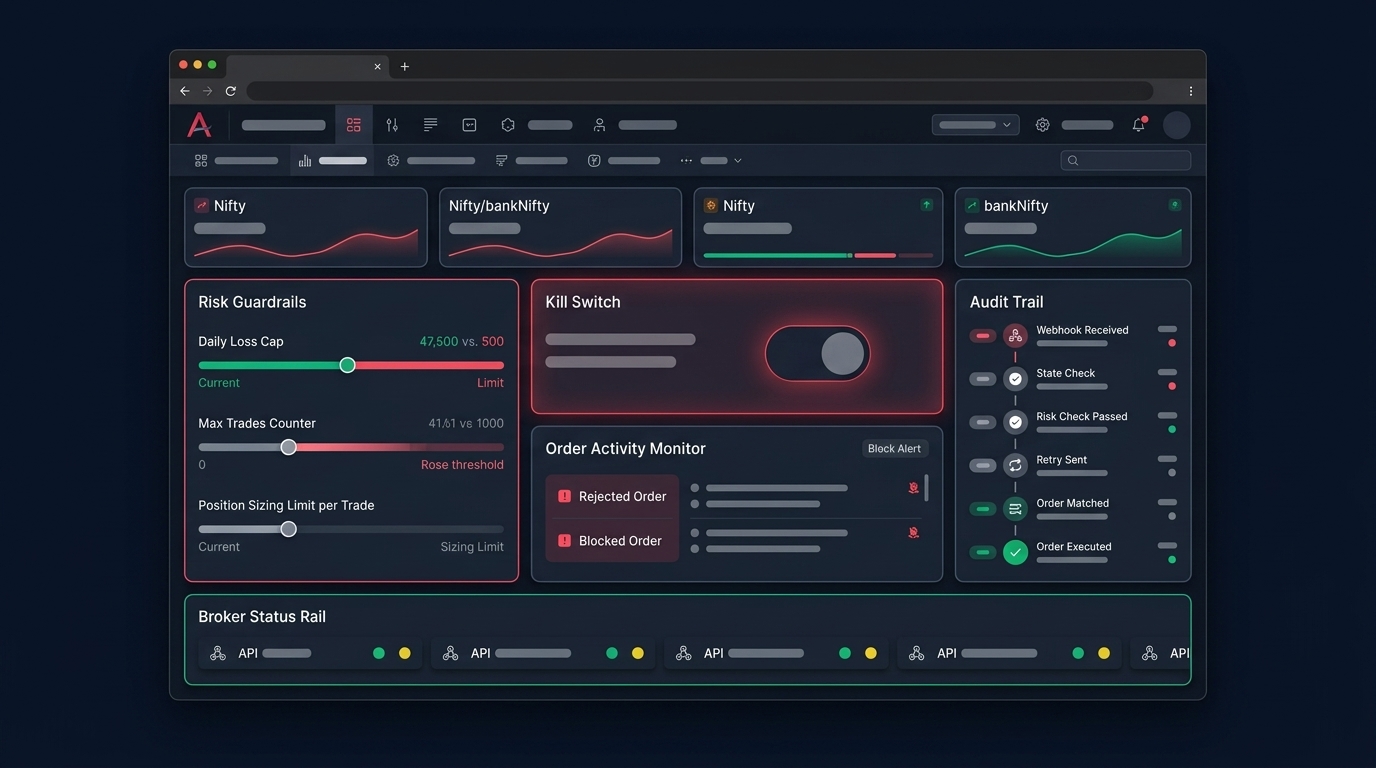
- A kill-switch can halt all new orders in one click, independent of the strategy code.
- Daily order count and gross exposure have hard caps that the system enforces, not just monitors.
If you are still building this layer yourself, platforms like Anadi Algo bake the dedup, state tracking, and kill-switch into the execution engine so you spend time on strategy logic instead of plumbing. You can try the workflow on early access and stress-test it on paper before any real capital moves.
Takeaway
Duplicate orders are almost never a "broker glitch." They are a missing idempotency key, a missing state check, or a retry that should have been a lookup. Fix those three and the category mostly disappears — and the rare case that slips through gets caught by your daily order cap before it becomes a real loss.